

You’re Fixing AI Inconsistency Wrong. Here’s What Works.
Skill file, context template, and what to add to your CLAUDE.md or AGENTS.md to fix it for good.

I created this skill for my Prosper newsletter that interviews me before every session. I simply right /draft-brief when I open a new Claude Code session and it runs the interview.
When I started this practice of running an interview before every session, the thing I noticed the most was not only the output got better, but the questions were also harder to answer.
And then I realized...that’s the point.
Yes, Claude misses parts of your CLAUDE.md. Yes, it drifts between sessions. The longer file wouldn’t be very helpful here. The fix is a different kind of document, a skill I’ll show you later in this post.
Let’s say you’re currently in a session where you’re working on a task.
You open Claude, start a task, and within twenty minutes you’re explaining something you already explained three sessions ago. The output is close but off in a way you can’t name, you had to explain some terminology again. You add a line to your CLAUDE.md. The next session improves briefly.
Then it starts to drift again.
Sometimes, Claude doesn’t understand what you mean, but it’s designed to be the best helper possible, so it interprets things as best it can.
Matt said it well in his video.
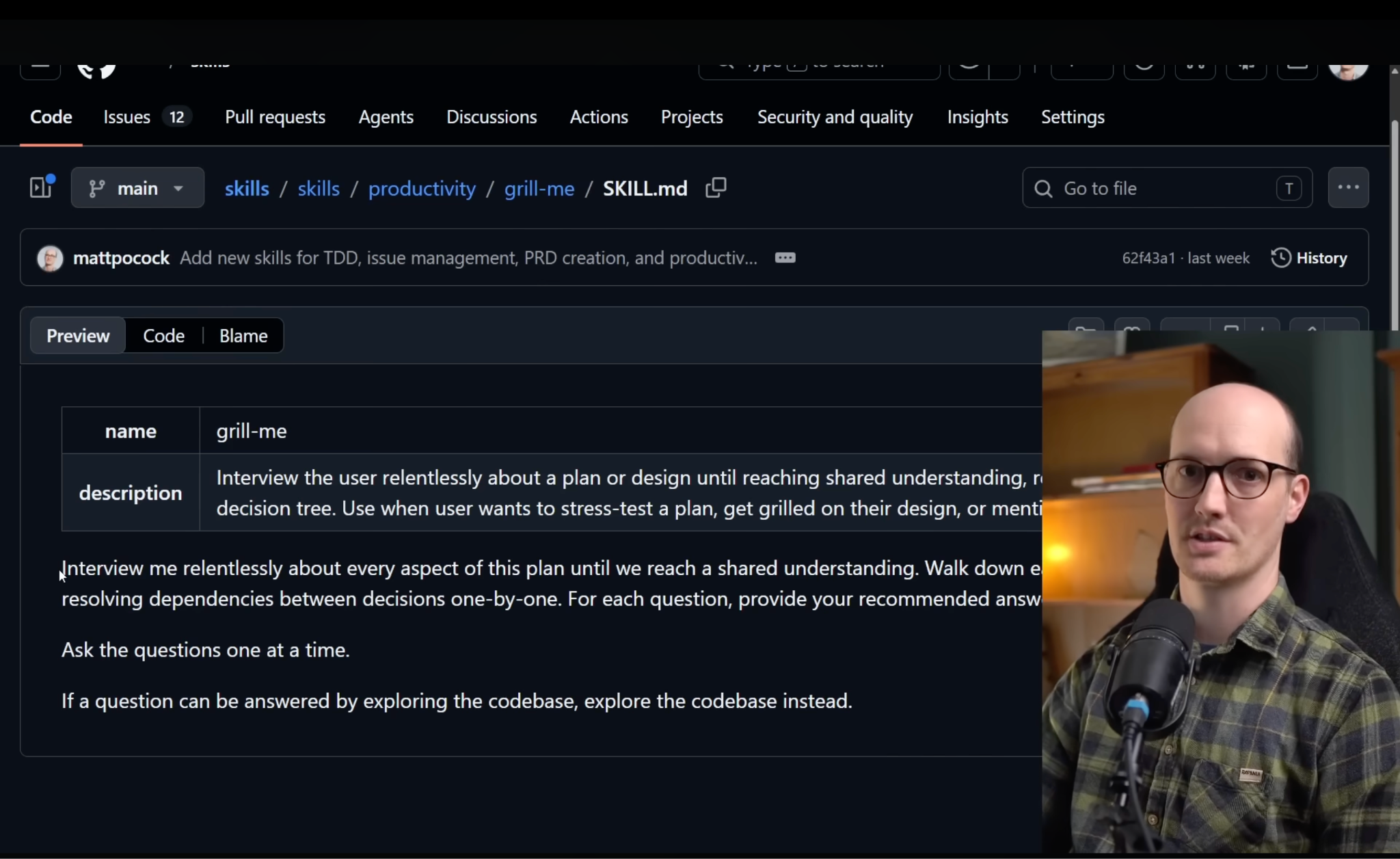
I first understood this properly watching Matt Pocock’s video:
on his /grill-me skill and where it falls short. He was describing the same problem for software engineers: during a session, you land on great shared language:
- Precise terms
- Agreed-upon definitions
- Real decisions
Then the session ends. Next session, you re-explain everything. His fix wasn’t a better prompt or a longer context file. It was an interview that forces decisions into precise language, then saves that language so the next session starts with it already loaded.
I realized I was using the same setup, but after watching the video from Matt, I built an improved system for Prosper.
The drift stopped.
With this post, you’ll get:
- The Brief skill file you can paste into any LLM or install in your AI Agent and invoke with /brief
- A context file prompt that builds your shared language layer in one session
- A folder structure for saving every brief so you can look back at what you decided and why
- What to add to your CLAUDE.md or AGENTS.md after this process
First, let’s go through what’s actually breaking.
The real problem with Claude inconsistency
 vs. with it (precise language, compounds each session")
Your CLAUDE.md is only a starting point.
When you write a context file alone, you write in the language that feels natural to you and not necessarily in language Claude can apply with precision. “Write like me” means something specific to you. Of course it makes sense!
But only in your brain.
To Claude, it means the statistical average of everything it’s seen described as a personal voice. That’s a very, very, very wide target.
Think of this inconsistency as a gap between what you thought you specified and what Claude understood you to specify.
The source of Claude’s inconsistency is missing shared language, not the model itself.
Once you see it that way, the solution is clear. You don’t need more instructions. You need better language. And the only way to get better language is to be interrogated until you produce it.
The standard fix tries to solve this with more instructions, but here’s why you probably want to re-think that...
Why CLAUDE.md isn’t enough

The common fix for Claude inconsistency is everywhere:
Write a better CLAUDE.md.
Add more specific instructions.
Add more examples.
Add “IMPORTANT:” or “YOU MUST:” before critical rules.
That advice isn’t wrong. A well-written CLAUDE.md helps. I’ve written about why static files fall short:

But there are a couple of problems with that approach:
You might forget something
Something you write can be a guess
But one that came out of an interview is a decision. That’s a bigger deal to me. It means whenever you were answering the questions, you had to REALLY think about what you will type, had to be precise and that precision is exactly what Claude uses.
When you write alone, you write what seems clear to you. What I noticed though, is when you’re being questioned, when the interview won’t let you move on until you answer in one specific sentence, you produce language that’s been pressure-tested.
I use a lot of this process for writing, and I dropped several articles already that were too vague. In the process of answering questions, I realized I couldn’t prove something or the point I was trying to make just wasn’t strong enough.
Claude’s native Memory saves facts across sessions:
Your name
Preferences
Things you’ve mentioned
But facts aren’t decisions. It records “Ilia writes a newsletter.“ It doesn’t know what “Spiky POV” means at the precision level where Claude can actually check work against it. The context file built through an interview does. You put it there deliberately, so you know exactly what Claude knows.
The system works in any domain:
Code
Research
Strategy
Client work
The language gap looks the same everywhere. So does the interview that closes it.
The system that closes the gap has two parts, and they have to work together.
What The Brief is: a 6-question interview before every session

Matt built his system for his own platform. The interview forces decisions into precise language. The shared language file saves the language so the next session starts with it already loaded. Together they fix the consistency problem, but neither alone does it.

The Brief is the same system applied to any domain.
There are two parts to it:
Part 1: The Interview.
Six questions, one at a time. You can’t move on until you’ve answered each in a single sentence. The harder a question is to answer, the more useful it is. That difficulty is exactly the language gap your AI was filling with guesses.
Part 2: The Context File.
A living document where answers accumulate. It’s not everything, but only what passes a three-question filter: Would you explain this again next session? Is it genuinely recurring? Does it already exist? All three yes, it earns a spot.
The system compounds. Each interview adds precision. Each session loads that precision. After a little while, Claude works with language you’ve actually tested, and not language you wrote once and hoped would hold.

Here’s what it looks like when the system runs on a real post.
How The Brief works in practice
I’ve been running this interview process for a couple of months now, and added a context file recently.
